Cloned every line.
Tuned every emotion.
Directed by you.
AinaVox isn't a one-click dubbing pipeline. It's an editor. Every line gets its own voice clone with a reference you pick, every scene gets the model that wins on it, and the timeline is yours — line by line, take by take.
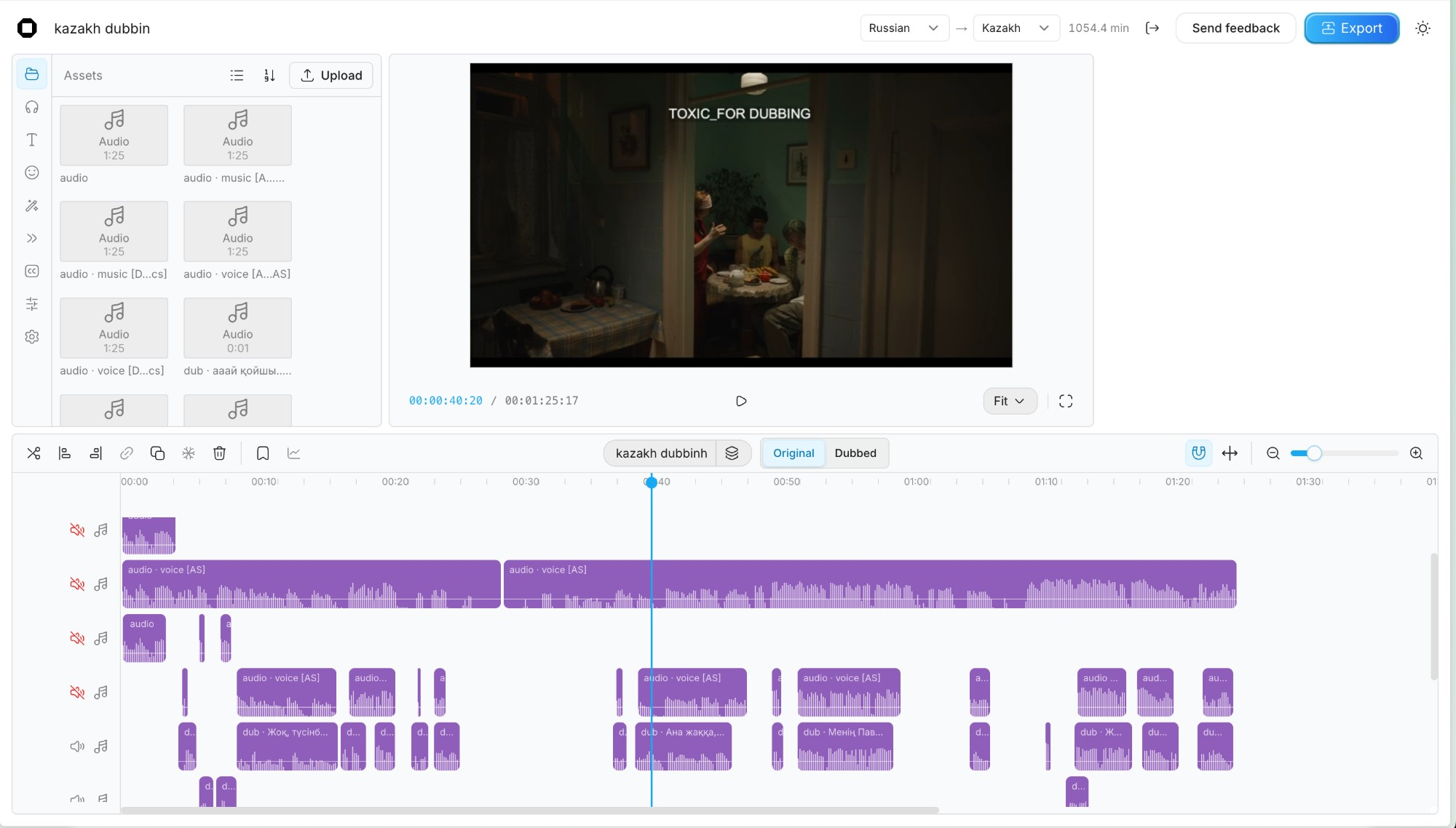
— a real timeline. every line on it. —
One clone per line.
Not one clone per film.
Other tools clone the voice once and reuse the same flat take for two hours of runtime. The fight scene sounds like the love scene. The credits read with the same energy as the climax.
AinaVox clones the voice again for every line, pulling the emotional register from a reference you pick on the timeline. Whisper, anger, grief, joy — each replica is a fresh take, dialed by you.
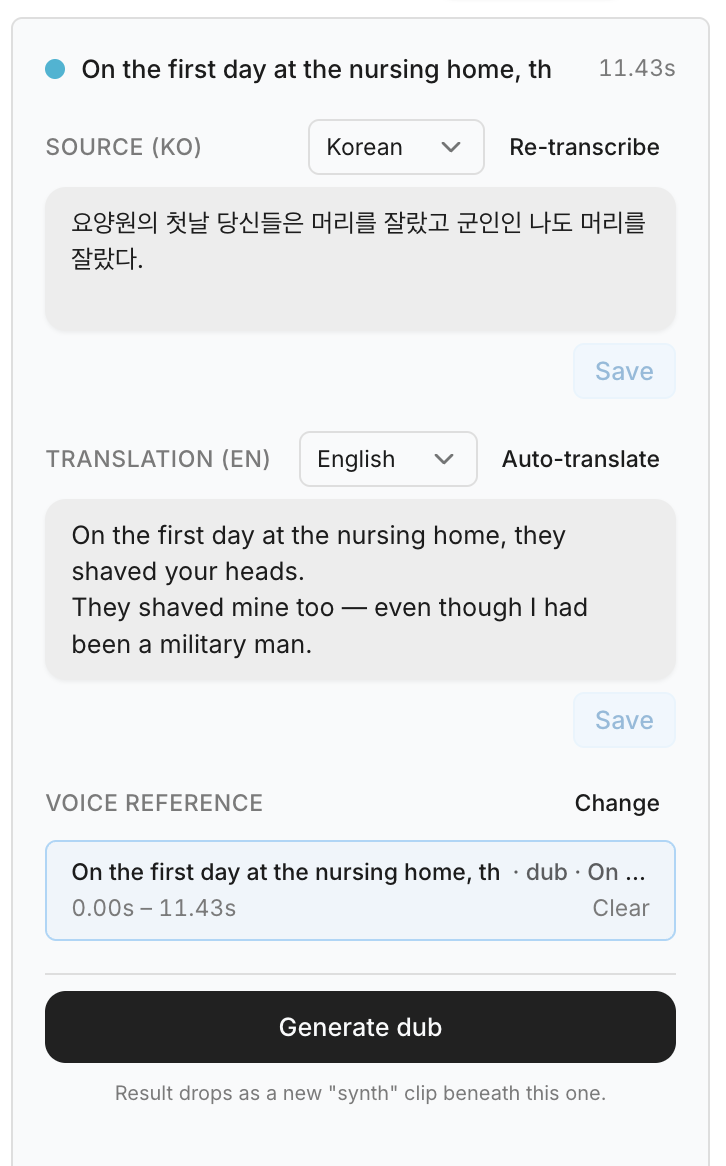
— per-line panel. one clip at a time. —
Direct the performance. Don't outsource it. The reference clip is the knob. You choose, the engine clones, the line lands the way you wanted.
Most AI dubbing is a button.
Yours should be a workspace.
One-click pipeline. Upload, wait, take what comes out. No timeline, no per-line control, no scene-level model choice.
Same flow. The voice drifts, the emotion is locked to the model's idea of 'neutral', and there's nothing on screen to edit.
One model handles every line, every scene — take it or leave it. Great voice tech, but you're locked in: can't swap in a better separator for a noisy scene, a sharper ASR for an accent, or a different TTS for a tricky character.
The protagonist's tender scene gets the same neutral read as the fight scene. The climax sounds like the credits. There's no knob to turn because the model is the product— and you're downstream of whatever it decided.
AinaVox flips it. A workspace where you direct each line, pick the reference, and choose the right tool for the right moment.
Different scene, different model.
Your call, not ours.
A two-hour film isn't one job — it's a thousand. Voice separation that wins on action films loses on solo dialogue. ASR that aces English dies on Hindi. We integrated the leading specialists and put every one of them in the editor — pick per scene, swap per minute, let the right model handle each moment.
- AudioShake CASS for clean dialogue extraction
- Our voice engine — emotional fight scenes hold tone
- Optional Sync Labs lip-sync
- Demucs for light separation (no orchestral score)
- WhisperX + pyannote for diarization
- Our voice engine per host, fresh reference per episode
- Google Chirp 3 ASR — strong on Indic languages
- Claude for context-aware translation with cultural notes
- Our voice engine with neutral narrator references — emotion light, clarity high
- AudioShake for clean dialogue
- Claude / GPT for context-aware translation
- Our voice engine with scene-by-scene emotional control
Open-source where it counts.
Best-in-class everywhere else.
Stop uploading.
Start directing.
Open the editor. Drop in a scene. Pick a reference. Hear AinaVox clone the line in your target language with the emotion you chose — then do it again for the next one.